Now in its sixth year of existence, the Open GLAM Survey has just undergone a significant overhaul. Here’s what has changed.

DeGolyer Library, Southern Methodist University, no known copyright restrictions.
Since Dr Andrea Wallace and I began the Open GLAM Survey in 2018, it has tracked galleries, libraries, archives and museums (GLAMs) making open access content available for re-use. It’s become the go-to reference for researchers, policy makers and practitioners working in copyright and digital cultural heritage collections. Today, it lists over 1600 institutions from 56 countries that have published open access data.
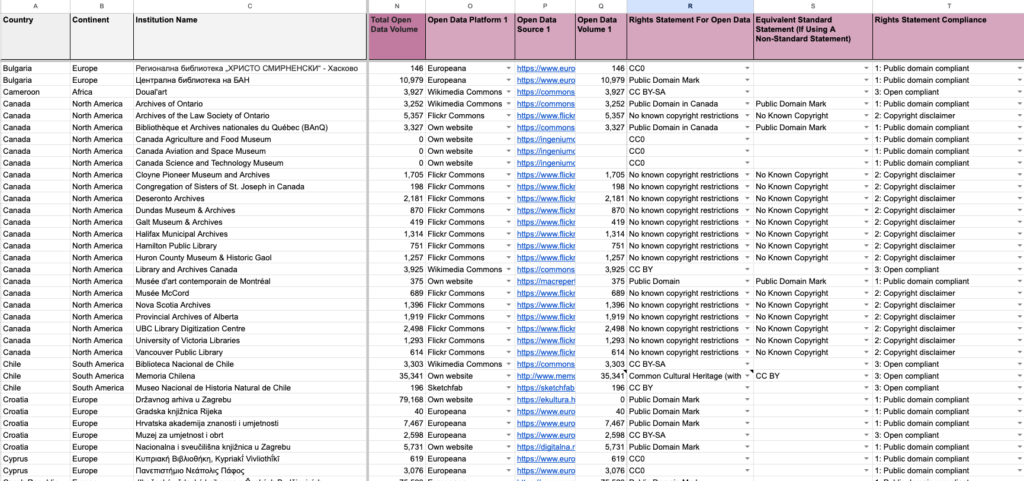
The survey has grown steadily in size and complexity. Housed in a publicly accessible Google Sheet, the survey has an extensive range of data points including institution type, geographic location, rights statements, APIs, terms of use and much more. To keep this information legible, whilst incorporating new data points and expanding the granularity of the data, Andrea and I have steadily optimised the Survey’s structure. This summer we’re releasing a significant new version – here are the key changes.
Better structured, more granular data
To enable more detailed recording and analysis of Open GLAM practice across multiple online platforms, the following columns have been duplicated (and populated where relevant) for every institution:
- Open Data Platform
- Open Data Source
- Open Data Volume
- Rights Statement for Open Data
English translations of institution names in the Survey have been added and fully populated with machine-generated translations. These are listed in a new column (D).
Complete documentation about the Survey’s structure is available in a new tab, ‘About this survey’. Explanatory text from a previous README Google Doc has been migrated and thoroughly updated.
Embedded visualisations of the latest data
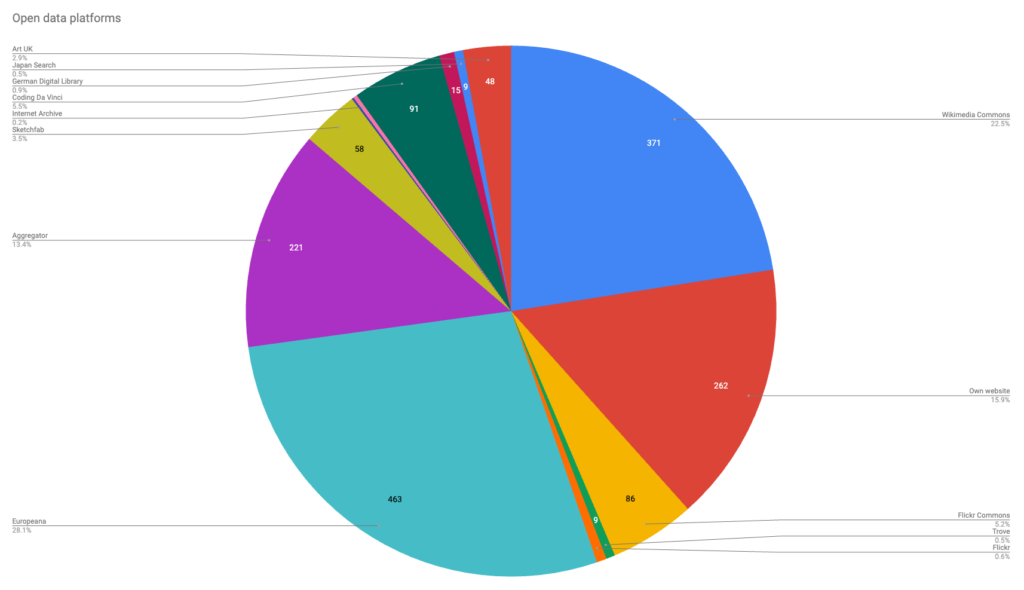
For the first time, we’ve embedded data visualisations directly within the Survey, using the Explore feature in Google Sheets. This means that anyone can access and download live, up-to-date visualisations of Open GLAM survey data for presentations, blogs, and so forth.
The following visualisations are now available in dedicated tabs:
- Instances by Country
- Instances by Continent
- Open licences and rights statements
- Rights statement compliance
- Open access scope
- Open data platforms
Complete coverage in Wikidata
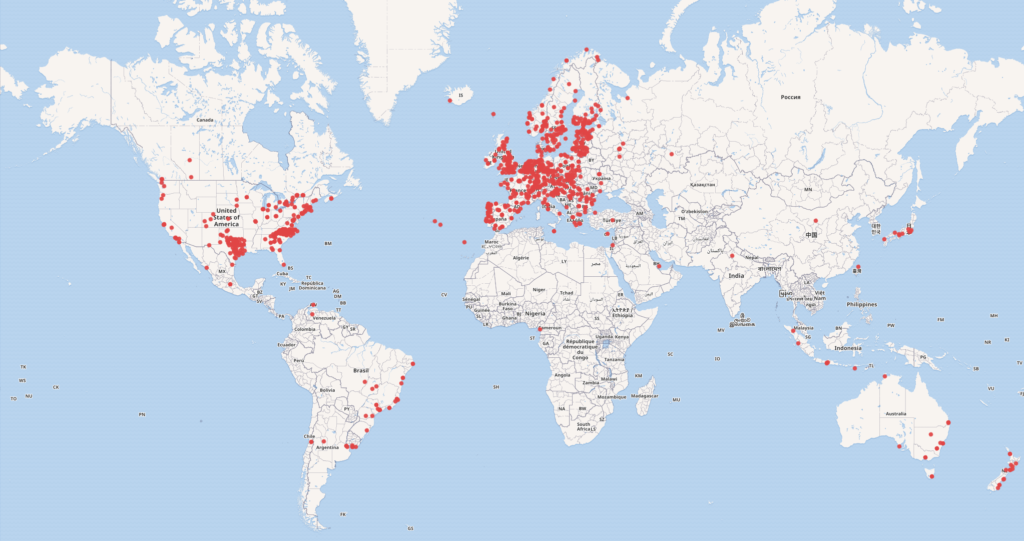
For several years the Open GLAM Survey has been recorded in Wikidata. Q73357989 is the principle item for the data set, and editions of the Survey over time are recorded as discrete Q items, for the purposes of annotation.
Now, for the first time, every institution in the Survey is represented in Wikidata. This enables the full data set to be queried and visualised on the platform. For instance, here’s a map visualisation of global Open GLAM instances, generated by a SPARQL query.
We hope you find these updates useful. If you have comments, questions or suggestions about the Open GLAM Survey, don’t hesitate to get in touch.